Framework
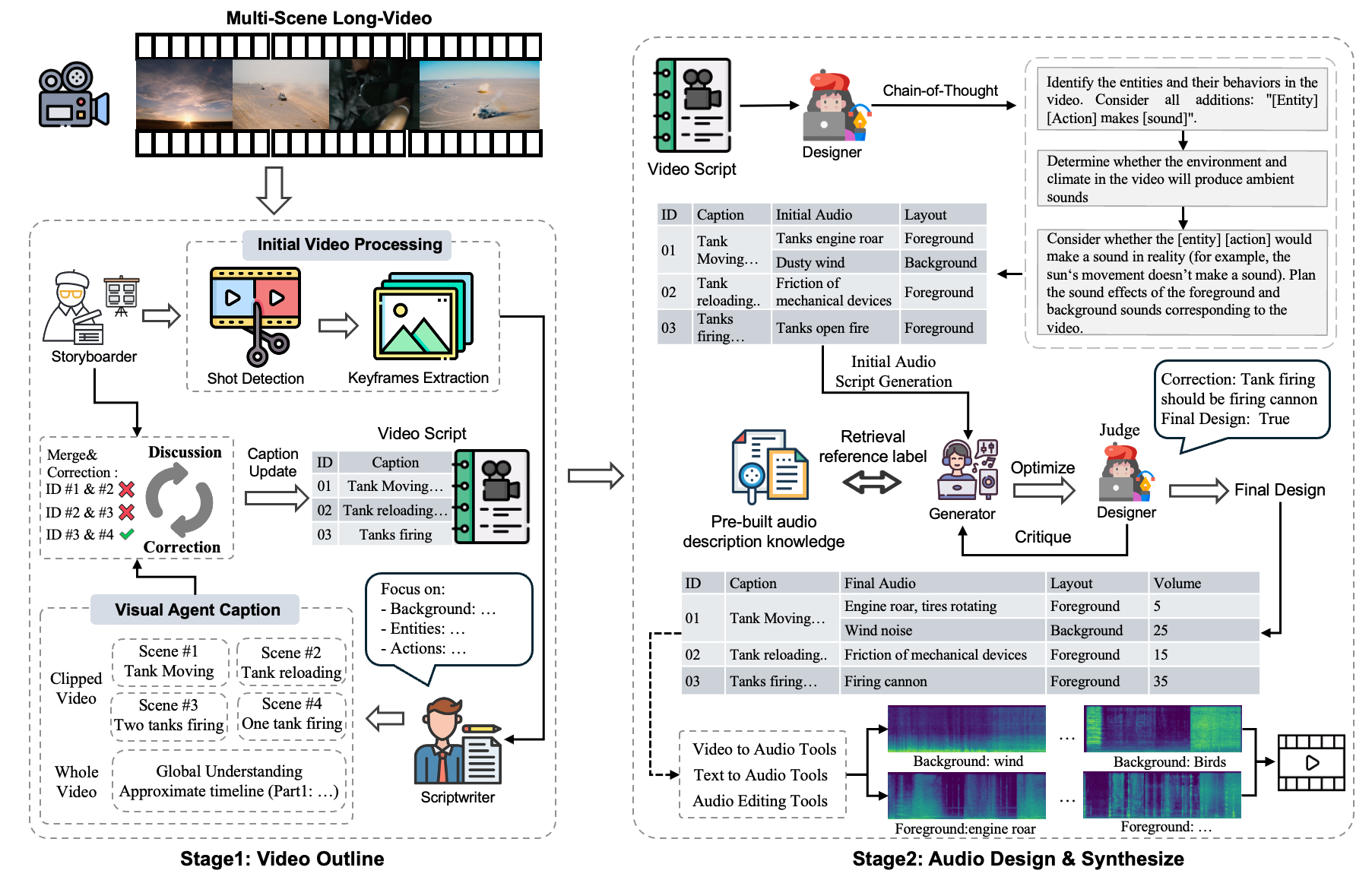
Figure 1: Overview of our LVAS-Agent multi-agent collaboration framework for long-video audio synthesis.
Video-to-audio synthesis, which generates synchronized audio for visual content, critically enhances viewer immersion and narrative coherence in film and interactive media. However, video-to-audio dubbing for long-form content remains an unsolved challenge due to dynamic semantic shifts, temporal misalignment, and the absence of dedicated datasets. While existing methods excel in short videos, they falter in long scenarios (e.g., movies) due to fragmented synthesis and inadequate cross-scene consistency. We propose LVAS-Agent, a novel multi-agent framework that emulates professional dubbing workflows through collaborative role specialization. Our approach decomposes long-video synthesis into four steps including scene segmentation, script generation, sound design and audio synthesis. Central innovations include a discussion-correction mechanism for scene/script refinement and a generation-retrieval loop for temporal-semantic alignment. To enable systematic evaluation, we introduce LVAS-Bench, the first benchmark with 207 professionally curated long videos spanning diverse scenarios. Experiments demonstrate superior audio-visual alignment over baseline methods.
Figure 1: Overview of our LVAS-Agent multi-agent collaboration framework for long-video audio synthesis.
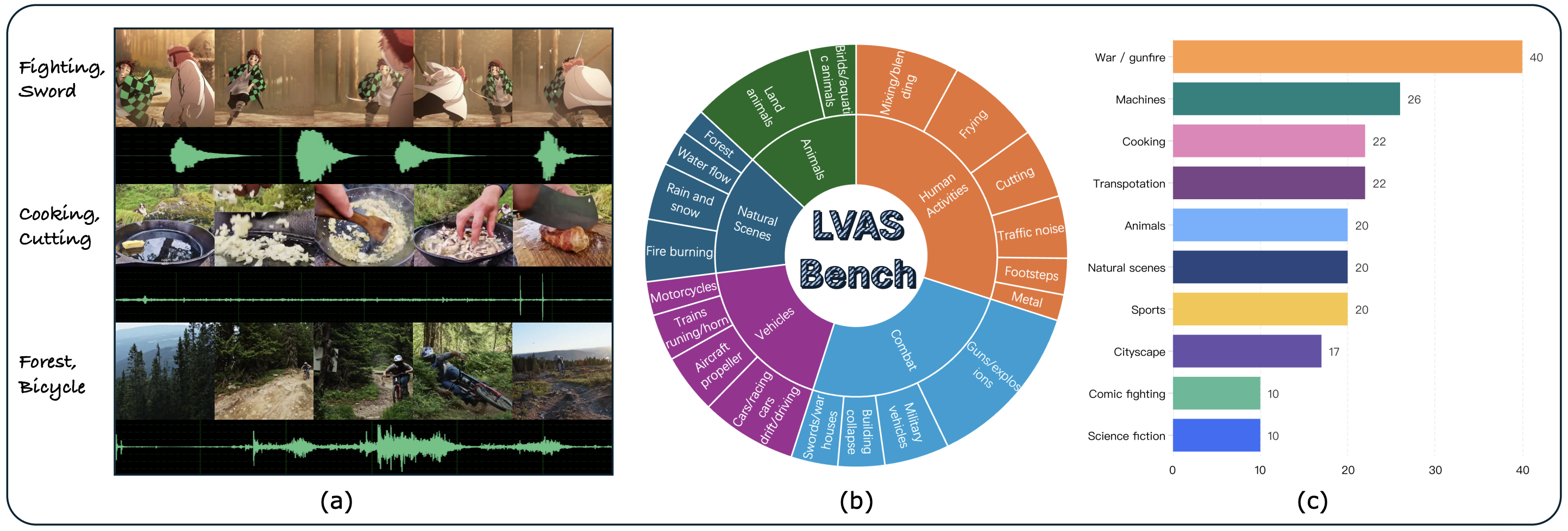
Figure 2: Our LVAS-Bench is presented in the following parts: (a) illustrates sample data from the benchmark, (b) provides statisticaldistributions of audio categories and sub-categories across the dataset, and (c) presents the statistics of video categories within the dataset.
Our method (right) achieves better audio-visual alignment compared to baseline methods (left)
Prompt: Wind, Tanks moving, Tanks firing
Our method achieves better temporal-semantic alignment
Prompt: Train passing and Train whistle
There is a clear distinction between the sound effects of high-speed rail operation and steam train operation, with subtle background sounds (Intermittent train whistle).
Prompt: Human Voice, Car racing
Audio types are more diverse and accurate: there are obvious audience voices, diverse vehicle driving sounds, and obvious vehicle collision sounds
Prompt: cat eating, explosion, liquid, arrow release whoosh
Reflect more sound effects.
Completed with the explosion, there is a running sound when the train passes by
@misc{zhang2025longvideoaudiosynthesismultiagent,
title={Long-Video Audio Synthesis with Multi-Agent Collaboration},
author={Yehang Zhang and Xinli Xu and Xiaojie Xu and Li Liu and Yingcong Chen},
year={2025},
eprint={2503.10719},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.10719},
}